

Kunstmatige intelligentie kan gezondheidsproblemen van mensen voorspellen, soms ruim tien jaar vooruit, zeggen onderzoekers. Een nieuw model leert patronen in medische dossiers te herkennen en schat de kans op meer dan 1.200 aandoeningen — een soort weersvoorspelling, maar dan voor de gezondheid van mensen.
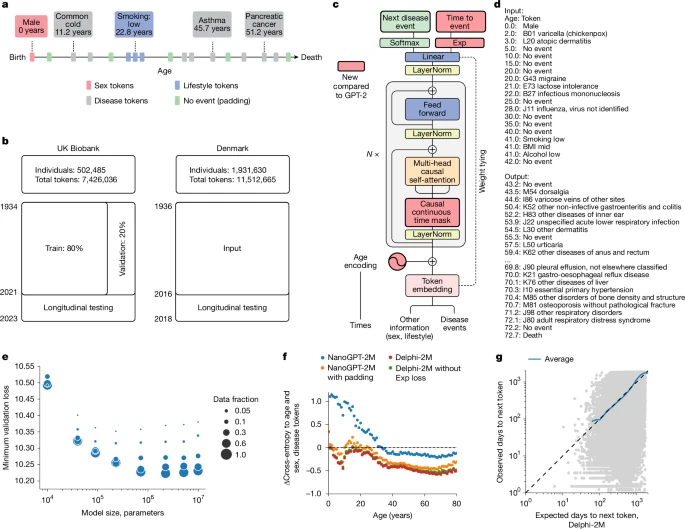
a. Schematische weergave van gezondheidstrajecten op basis van ICD-10-diagnoses, leefstijlgegevens en zogeheten healthy padding tokens, telkens vastgelegd op een specifieke leeftijd.
b. Opleidings-, validatie- en testgegevens, afkomstig van de UK Biobank (links) en de Deense ziekteregisters (rechts).
c. Architectuur van het Delphi-model. De rode componenten geven de aanpassingen weer ten opzichte van het oorspronkelijke GPT-2-model. ‘N ×’ staat voor het herhaald toepassen van het transformerblok, N keer achter elkaar.
d. Voorbeeld van een modelinput (prompt) en modeloutput (samples), bestaande uit paren van (leeftijd:token).
e. Schaalwetten van Delphi: de optimale validatieverliesfunctie uitgezet tegen het aantal modelparameters, voor verschillende groottes van trainingsdata.
f. Resultaten van ablatie-experimenten, weergegeven als verschillen in cross-entropie ten opzichte van een leeftijd- en geslachtsgebonden basislijn (y-as), bij verschillende leeftijden (x-as).
g. Nauwkeurigheid van de voorspelde tijd tot een gebeurtenis. Waargenomen (y-as) en verwachte (x-as) tijden tot gebeurtenissen worden weergegeven per volgende tokenvoorspelling (grijze stippen). De blauwe lijn toont het gemiddelde over opeenvolgende intervallen op de x-as.
Wat is Delphi-2M?
Het model, genoemd Delphi-2M, gebruikt dezelfde algemene onderliggende techniek als bekende AI-chatbots: het is getraind om patronen en opvolgingen te herkennen en daarom te ‘voorspellen wat er daarna komt’. In plaats van zinnen te vervolgen, voorspelt het welke aandoeningen en medische gebeurtenissen waarschijnlijk volgen uit iemands medische historie en leefstijlinformatie. Het model schat niet exacte data (het zegt bijvoorbeeld niet dat je op 1 oktober een hartaanval krijgt), maar geeft waarschijnlijkheden — vergelijkbaar met een voorspelling van “70% kans op regen”.
Hoe is het getraind en getest?
Delphi-2M is gestart op anonieme medische gegevens uit het Verenigd Koninkrijk: ziekenhuisopnames, huisartsenregistraties en leefstijlinformatie zoals roken, afkomstig van honderdduizenden deelnemers (ruim 400.000). Daarna is het model gevalideerd op data van andere deelnemers en uiteindelijk getest op een grote dataset uit Denemarken met 1,9 miljoen medische dossiers. Die externe tests laten zien dat de voorspelde kansen in die dataset redelijk goed overeenkomen met wat er daadwerkelijk gebeurt: als het model bijvoorbeeld zegt dat iemands risico 1 op 10 is voor het komende jaar, blijkt die voorspelling in de Deense data vaak inderdaad ongeveer één op tien te zijn — het model lijkt dus goed gekalibreerd in die populatie.
Waar is het model goed in — en waar niet?
Delphi-2M haalt de beste resultaten bij ziekten met een duidelijke, voorspelbare progressie. Voorbeelden zijn type-2-diabetes, hartinfarcten en sepsis: aandoeningen waarvan het verloop en de risicofactoren meestal relatief systematisch zijn en in de data te herkennen. Voor meer “willekeurige” gebeurtenissen — zoals sommige infecties die sterk afhangen van toevallige blootstelling — zijn de voorspellingen minder betrouwbaar.
Wat kun je met zulke voorspellingen?
De onderzoekers stellen zich diverse toepassingen voor, altijd onder voorbehoud dat het systeem nog gereguleerd, getest en verantwoord moet worden ingevoerd:
-
Vroege interventie voor individuen: mensen met verhoogd risico kunnen gericht preventieve maatregelen krijgen, zoals leefstijladvies of medicijnen. Als voorbeeld: nu worden mensen soms al statines voorgeschreven op basis van een berekende kans op hartaanval of beroerte; iets soortgelijks zou mogelijk met AI-gedreven risicoberekeningen kunnen gebeuren.
-
Gerichter gedragstoezicht en advies: bijvoorbeeld gerichte adviezen om alcoholgebruik terug te dringen bij mensen die volgens het model extra risico lopen op bepaalde leveraandoeningen.
-
Scherper screeningsbeleid: voorspellingen kunnen helpen bepalen wie baat heeft bij intensievere screening voor specifieke ziekten.
-
Zorgplanning op populatieniveau: door alle medische dossiers in een regio te analyseren zou het systeem ziekenhuizen kunnen helpen anticiperen op toekomstige zorgbehoefte — bijvoorbeeld inschatten hoeveel hartaanvallen er per jaar in een bepaalde plaats verwacht worden, zodat capaciteit en middelen beter gepland kunnen worden.
Beperkingen en ethische/technische aandachtspunten
Het model is nog niet klaar voor routinematig klinisch gebruik. Belangrijke aandachtspunten zijn onder meer:
-
Bias in de data: de oorsprongsdataset is voor het grootste deel samengesteld uit mensen van ongeveer 40–70 jaar. Daardoor kan de voorspellende waarde afnemen voor jongere of juist veel oudere groepen, of voor bevolkingsgroepen die ondervertegenwoordigd zijn in de trainingsdata. Dat maakt generalisatie naar de hele bevolking onzeker zonder extra aanpassingen en testen.
-
Ontbrekende datatypes: huidige versies werken vooral op medische dossiers en leefstijlinformatie; onderzoekers werken aan uitbreidingen met beeldmateriaal (scans), genetische informatie en bloedwaarden. Zulke extra informatie kan de nauwkeurigheid verbeteren, maar roept ook nieuwe privacy- en ethische vragen op.
-
Kalibratie en validatie: zelfs met goede prestaties in een of meerdere externe datasets moet het systeem uitgebreid worden gevalideerd in diverse gezondheidszorgsystemen en etnische groepen voordat het klinisch ingezet kan worden.
-
Regulering en verantwoorde implementatie: gebruik in de praktijk vereist duidelijke regelgeving, transparantie over beperkingen en zorgvuldige patiëntcommunicatie — om onnodige alarmen of ongerechtvaardigde behandeling te voorkomen.
Wat zeggen de onderzoekers?
Onderzoekers benadrukken dat dit vooral onderzoekswerk is: de technologie bestaat en laat veelbelovende resultaten zien, maar “alles moet getest, goed geregeld en zorgvuldig doordacht worden voordat het wordt toegepast in de zorg.” Ze vergelijken het invoeren van dit soort voorspellende AI in de gezondheidszorg met de lange weg die de toepassing van genomica aflegde — eerst wetenschappelijke zekerheid, daarna jaren van geleidelijke invoering in de klinische praktijk.
Samenvattend
Delphi-2M toont dat generatieve AI-modellen medische dossiers op grote schaal kunnen lezen en gebruiken om waarschijnlijkheden voor duizenden aandoeningen uit te rekenen. Dat opent mogelijkheden voor preventie, gepersonaliseerde zorg en betere planning van zorgcapaciteit. Tegelijkertijd zijn er nog belangrijke technische, demografische en ethische beperkingen; de methode vereist verfijning, bredere data en strikte toetsing voordat hij in de dagelijkse klinische praktijk kan worden gebruikt.
Door: Drifter
Aanbevolen Reacties
Er zijn geen reacties om weer te geven.
Log in om te reageren
Je kunt een reactie achterlaten na het inloggen
Login met de gegevens die u gebruikt bij softtrack